Thanks to wordpress.com for creating a great product, and for many years of solid service which enabled countless creators and writers to talk about whatever was on their minds. I wish you all the best.
The decision to move to a self-hosted blog is purely out of a need to maintain my independence of thought.
Like many others, I’ve been shocked by the urge to engage in politically-correct censorship from formerly free-thinking tech platforms–and I find myself needing to limit my dependence on any company willing to give in to the anti-free-speech mob.
As someone once put it: the way to stop tyranny isn’t to wait until one brave person takes 10 steps forward to fight (and gets killed for his efforts!); it’s for all of us to take one step forward and simply say, “No.”
Despite everyone’s diligence and best intentions, it looks like the only thing which stops Covid from spreading is letting 15-25% of the population catch it, trigger an immune response, and (in almost all cases) shrug off the effects. It then becomes harder to pass on to the next person, and the overall infection rate tapers off, along the lines suggested by of Farr’s Law on epidemics.
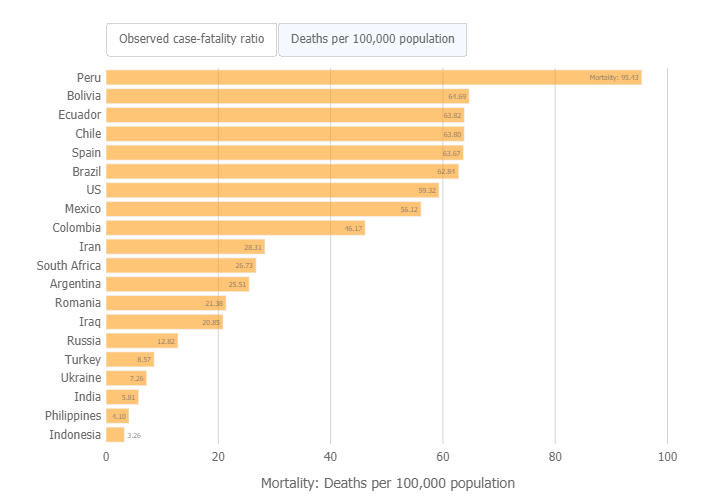
Within this framework, I’d like to believe that it’s still possible to largely shield old folks from catching the disease, and that seems to be where our energy ought to be devoted. But as hard as we all tried to live in our little hermetic bubbles, there’s been virtually no correlation between lockdown efforts and the overall fatality rates, world-over. At great economic and human cost, it’s been possible to delay infection, but in the end, there’s been no stopping it from working its way through the populations, even of countries like Peru which used a heavily militarized approach to ensure enforcement of their draconian lockdown measures.
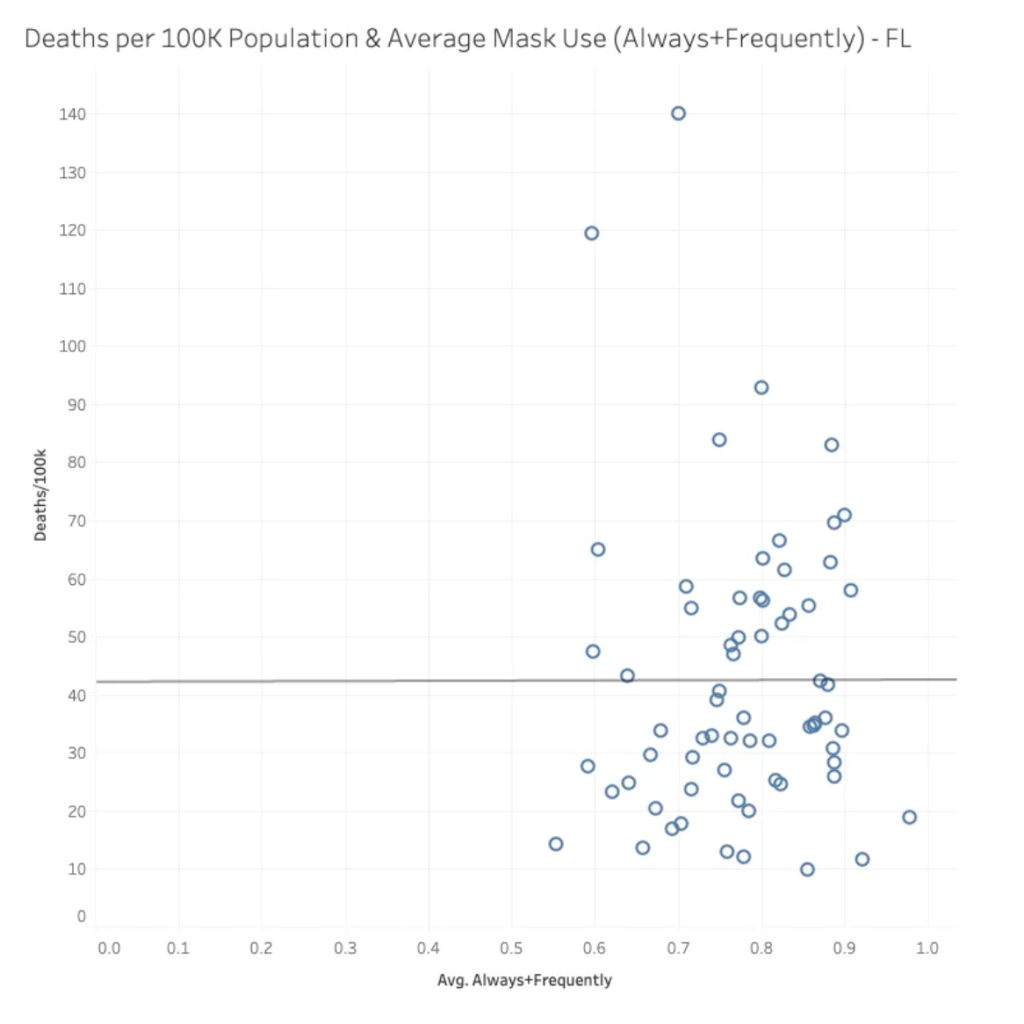
Mask use seems similarly ineffective. See if you can spot the correlation between mask use and deaths/100,000 in the scatter graph below. If you can, I’ll buy you the socially-distanced drink of your choice:
So what are we to do?
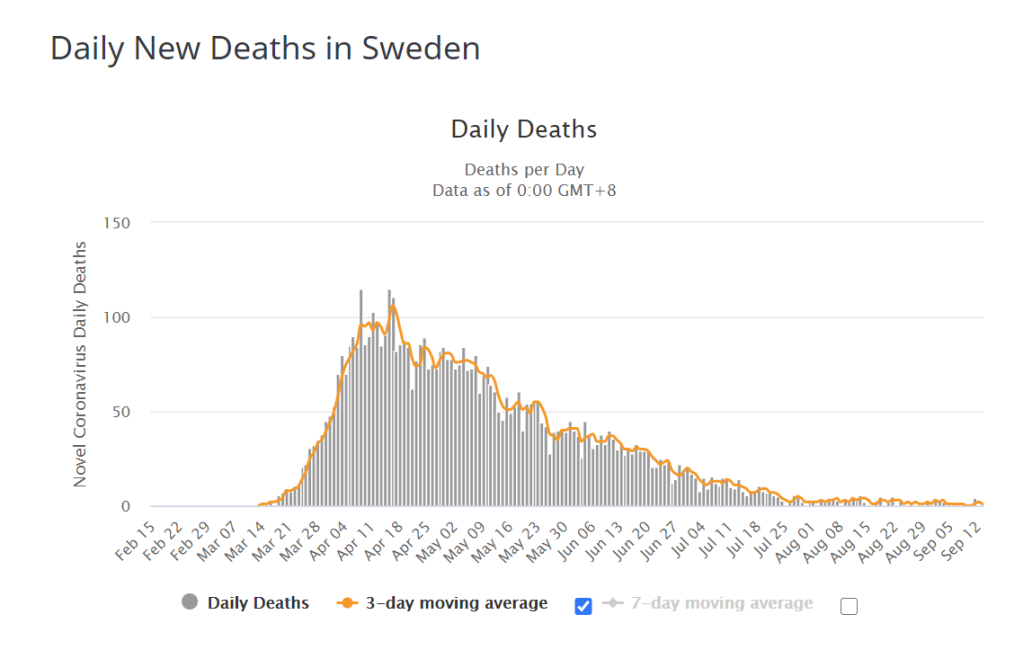
I can’t believe I’m typing this, but as an American, I’m jealous of Sweden. They didn’t lock down, and didn’t destroy their economy. Instead, they took their hit, moved on, and now their Covid death rate is now essentially nil.
For all practical purposes, Covid in Sweden is done. Hell, they were done almost two months ago:
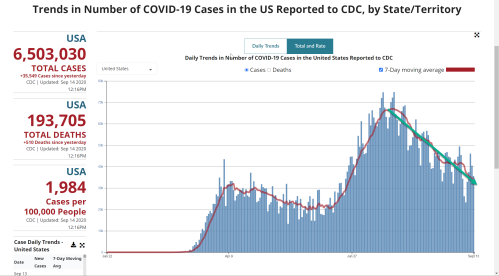
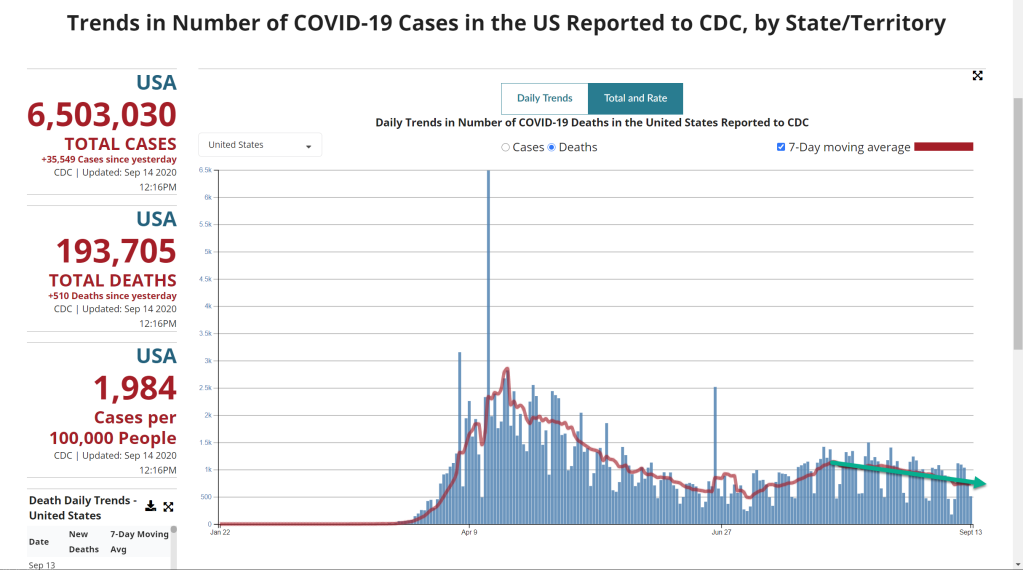
As for us, at least the trend lines say we’re well on our way to reducing this to a tolerable nuisance in life, even given the incentives to overcount on both infections and deaths:
Source: CDC. Green trend lines added to emphasize post-inflection direction.
Granted, all of this is as of September 14th, 2020, and things can change. At this point, though, my money is on the trends continuing until it falls into the range of “background threat” of a type with the seasonal flu. Covid-19’s never going away entirely, but it’s far past time for us to drop the posturing and political shenanigans associated with it and get back to living life.
…but given the nature of politics (and that this thing long ago morphed into an issue more political than public health-related), I for one, am not holding my breath.
Standard disclaimer: This is one of those “how to overcome an incredibly geeky tech problem which has been bedeviling me forever” posts. It’s meant as a virtual breadcrumb for anyone who faces a similar issue. If you find it and it helps, please give it a “like”. If this isn’t the sort of thing that interests you, by all means skip on to the next comic, music, or pop culture-related post.
Anyone who’s ever done Windows Forms coding knows what a pain in the nether regions it’s been to get windows and type to properly handle monitors with different resolutions. (I wrote about it years ago here)
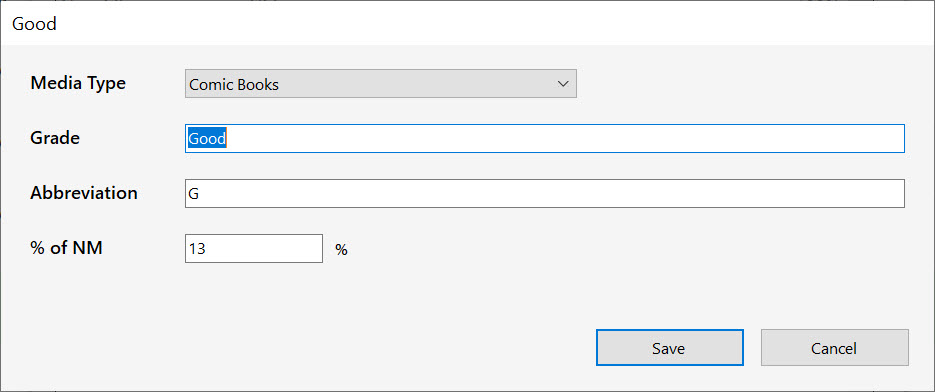
Things got substantially better with the introduction of .Net Framework 4.7.2, which started to make it possible to properly scale things when you had multiple monitors with different resolutions. Still, there were certain actions–such as dragging a screen from a hi-res 4K monitor set to 150% magnification to a regular monitor set at 100%, that would give results like this:
Dialog as it appears on the 4K monitor, set at 150% display scale
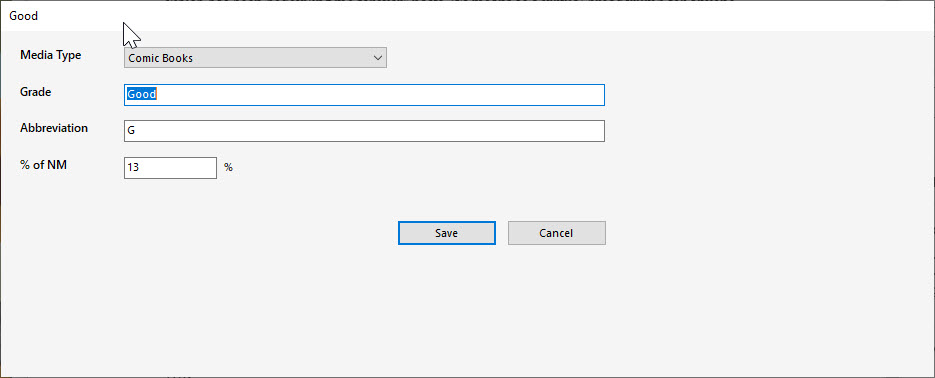
…becoming this
Same window, when dragged to a monitor set at 100% display scale
…when dragged to the adjacent 1080p monitor, whose display scaling was set to 100%. Note the sea of white space at the right and bottom. This occurs even when there is no program code to setup the window.
Worse, when dragging the window back to the original monitor, the white space remains–or even grows (in some cases, enough so that repeatedly dragging the window back and forth fills the entire screen).
Granted, it’s possible to manually compute your own window scaling factors, and resize and scale every element as necessary whenever the form was moved, but this is beyond tedious in practice–and it makes dragging forms around both slow and ugly to boot. You also need to test that you’ve handle any screen DPI switches that happen simply when the user switches up their display settings in the control panel–another can of worms.
Setting both monitors to the same scaling factor removes the problem, but that’s also not really a solution.
So what is the solution? It turns out it’s two things: one of which makes sense, the other which appears to be a bug in .Net’s rendering algorithm.
The default setting of any Windows form’s “AutoSizeMode” property is “GrowOnly”. This needs to be overridden on every form to be “GrowAndShrink”.
The culprit behind the growing white space, however, was the anchor property of the bottom buttons(!). One might reasonably assume that since the action buttons are meant to be placed dependent on the position of the lower-right of the window, that anchoring them to the bottom-right of the form makes sense. (This is exactly what you’d do if the window was capable of resizing: you’d always want the buttons to ride at the bottom-right of the form).
The bug apparently comes, however, in that setting the buttons to be anchored to the bottom right of the form messes up .Net’s calculation of how large the form should be when moved between windows of different dpi/scale. .Net seems to effectively scale up the form according to the old dpi setting, peg its boundaries at where the anchored items would be, then re-lay it out according to the new monitor’s dpi–leaving the white space you see there.
The solution? On any fixed size form, avoid anchoring any elements to the bottom or right of the form.
It took a long time to figure out what was going on and fix it. Now I just have to check over about a jillion dialogs and forms in ComicBase, and my next Livestream (which inevitably involves showing something on my secondary monitor which was dragged over from my 4K primary monitor) should go a little smoother…
I recently decided to start up a ComicBase Livestream, so that I (your friendly neighborhood ComicBase creator) could reach out to the folks directly, and answer your questions live through the magic of internet broadcasting.
In the interest of aiding all who are considering setting up their own broadcast, here’s a few of the bits of technical trivia I’ve learned in the past two weeks as a newbie livestreamer:
“AFV” means “Audio Follows Video”. It also means that if you push the little button marked “AFV” on your ATEM Mini Pro switcher, you’ll be activating your video camera’s tinny little built-in microphone any time you switch the shot to the camera. The switcher then adds that audio to the sound from the big condenser microphone you had plugged into the switcher’s separate “Mic” port, giving your a bitchin’, doubled-up boomy sound. If you’re a student of audio engineering, you’ll recognize that this as reminiscent of the trick used to record David Bowie’s “Heroes”… except that it sucks.
The ATEM Mini Pro switcher is a fantastic piece of gear–basically giving you a portable TV switching console with the ability to directly livestream right from the switcher. But it lacks a headphone jack, so you’ll never hear the boomy AFV thing until you play back the audio after the livestream.
The FocusRite Scarlett 2i2 audio interface I sprung for in order to be able to use a decent condenser microphone for the shoot is also wonderful… but it only has one set of outputs. This means that if you have those going to your speakers so you can hear your computer, you can’t also send the output to your video switcher to take in the sound of the condenser microphone you’re using the Scarlett’s phantom power for. For about a day, I fooled around with various Y-cable scenarios, but eventually gave up and realized I just shoulda bought the more expensive Scarlett 8i6 in the first place. Which I then did. If you need a lightly used 2i2, please reach out: it’s going cheap.
If you want the big AT-4033 condenser microphone you’ve suspended on a boom stand to not slowly drop from the top of the frame into the center of your desk while shooting, there’s a trick. It is not, as it turns out, to wrench the tightening knob on your boom as hard as you possibly can (won’t work, strips the mechanism), but instead to suspend a small sandbag counterweight on the far end of the boom. Physics: the ultimate Lifehack!
My wonderful (and expensive!) Canon 5d Mark III camera will apparently auto-stop recording at 29 minutes, 59 seconds (a “feature” built into most DSLR cameras designed to avoid being classed as a “video camera” for EU taxation purposes). This is less than great if you suspect you might want to talk for 30 minutes or more.
On the other hand, the more-than-a-decade-old Canon HF-100 handycam I scrounged from my back closet works beautifully for shooting the video. But it also has an uncanny ability to auto-focus on the boom microphone I intentionally left in the shot, leading the focus on my face to be a little soft. This is flattering for hiding my increasing number of wrinkles, but is not a standard cinematographic artistic choice.
The reason almost every YouTube livestreamer except the truly professional begins their streams by staring blankly at the camera is that they’re watching YouTube’s preview window to see if it’s actually picking up their video feed before they click the “Go Live” button to start broadcasting the stream. After clicking that button, YouTube then apparently randomizes the starting frame by +/- 3 seconds in order to capture that uncomfortable staring look you had going as you waited for the video to appear in preview.
Live chat is amazing–but it scrolls by really quickly, and it’s nigh-impossible to catch anything but a tiny amount of the discussion until after the stream is over.
Despite all this, Livestreaming is a blast! I’ll be continuing to do it each Wednesday at 4pm Central, no doubt making new and creative mistakes each broadcast–and having a great time answering viewer questions, talking about new and obscure ComicBase features, and what have you. Please check out the channel here, and do the old “Like and Subscribe” thing to help spread the word, and get notified of new broadcasts!
Several days ago, I decided that I needed to rearrange my entire office space in order to set it up for better videoconferencing–maybe even a podcast. As such, having a giant window immediately behind me as I sat at my desk was hardly ideal, since it turned every videocam shot of me into a backlit silhouette. While this sort of picture has its uses–particularly when portraying informants against the drug cartels–it didn’t make for a particularly photogenic teleconference image.
In the process of knocking about all the desks, office equipment, and electronics in my office, I unfortunately managed to send my venerable M-Audio AV40 speakers crashing to the ground, rendering them forevermore silent. My meager skills with a soldering iron could not resurrect my old friends, so I had to consign them to the trash heap.
After doing my usual rounds of internet searching on the current state of semi-affordable audio speakers for my computer, I was about to sink $499 into some decently reviewed AudioEngine A5+ speakers, when at the last minute, I decided to give the PC Editors Choice Edifier 1280Ts a shot. “What the heck” I thought–they’re only $99.99, so if they wind up being terrible, I can pass them on to [one of the less audio-obsessive members of the household] and go buy the AudioEngines…” Yes, I’m that awful.
As it turned out, Amazon came through even in the midst of a worldwide Coronavirus shutdown and dropped off a package with the new speakers less than a day after I’d ordered them. A couple of minutes later, I had them plugged in and sitting on the stands to either side of my computer, and fired up Pandora.
Nothing. Dead silence.
“Oh yeah” I remembered, and actually turned them on by pressing the power button in the back of the left speaker.
…and they were amazing.
After taking off the cheap-looking and sound-coloring speaker grilles, these little speakers really shone. There’s simply no way you can reasonably expect to get this sort of sound from speakers in this price range. I haven’t gotten out any audio analysis tools yet, but to my ear, they deliver a beautifully flat sound, uncolored by either the fake bass boosts of most smaller speakers, or the tinniness that tends to color cheaper speakers of this class. Better yet, they deliver a beautifully detailed stereo image that manages to crisply reproduce percussion and guitar while keeping a full warmth throughout the midrange and into the very (but not extremely low) bass.
The only real limits that are apparent after an hour of listening are for extremely low–even sub-sonic bass (think: 80hz and below). There are, after all, some physical limits to what speakers of this dimension can do. That said, while these wouldn’t be either my movie soundtrack or industrial dance club speakers of choice, they’re performing brilliantly throughout the range of actual music. In all, they perform much more like a high-end set of bookshelf recording studio monitors than the “better than your average computer speaker” M-Audios they replaced. I couldn’t be happier.
And I still can’t get over the idea that they only cost $99.95.
Clearly I have to destroy my tech gear more regularly…
Apocalarpers stocking up on toilet paper and bottled water
“LARPing” is “Live Action Role Playing” — basically getting together with a bunch of like-minded folks and dressing up as warriors or wizards or vampires etc. and acting out a live game of Dungeons and Dragons (or Vampire: The Masquerade, or what have you).
In our current state, it looks like we’ve decided to engage in a society-wide epic of “Plague!: The Apocalypse”. Although considerably less fun to play than any of the previously mentioned games, it’s become a worldwide sensation. In fact, many states and cities now mandate participation.
After an initial “setup” stage where everyone runs around in attempt to find as much toilet paper as possible, the players mostly just sit on their phones and computers at home, reading news headlines and trying to avoid getting bored. Players are allowed to move to other locations, but only after guiltily forming an excuse as to why the trip was absolutely necessary, and making efforts to stay at least six feet away from the other players (3 times that distance if any of the players is wearing a surgical mask).
Anyone who coughs or sneezes for any reason is a “carrier” and is instantly shunned by the other players. Any location that person has been in for the past two weeks is then shut down and the “carrier” is put in “quarantine”. After the first week of gameplay, however, this matters less since all the other locations shut down too, the entire economy goes into a tailspin, and the players are all effectively living in isolation anyway.
When Amazon began their project to act as the world’s online all-in-one shop, they knew they’d need to build one hell of a data center operation to cope with the demand. And they did it. Quite brilliantly, in fact.
Then they realized that by building worldwide data centers sufficient to cope with the worst of the peak demand (think: Christmas), they’d inevitably be overbuilding, leaving 95% of the capacity free most of the time. Why not do something with all that excess data center capacity…like, rent it out to other folks?
That, so the legend goes, was the genesis for what became known as Amazon Web Services (AWS), which has now grown to encompass countless services and computers spread across numerous connected data centers around the world. Their services now power everything from e-commerce to Dropbox to the Department of Defense. Indeed, if AWS ever does suffer one of their very-rare outages (the last I recall was a brief outage affecting their Virginia data center a year or so ago), it brings down significant parts of the internet.
We became a customer of AWS almost a decade ago, to help us serve up the installer images and picture disks in ComicBase over their “S3” (“Simple Storage Solution”) platform. Then, when I made the decision to move my family to Nashville and we had to split the IT operations in our California office, we decided to move our rack of web, database, and email servers up to Amazon’s cloud. AWS promised to let us spin up virtual servers and databases–essentially renting time on their hardware–and assign as much or as little resources as it took to get the job done.
It took us about a month to get the move done, and it was terrifying when we turned off the power to our local server rack (it felt like we were shutting down the business) . But to our great relief, we were able to walk over to a computer in our office outside our now-silent server room, fire up a web browser, go to www.comicbase.com, and see everything working just the way it should, hosted by Amazon’s extraordinary EC2 (“Elastic Compute Cloud”) and RDS (“Relational Database Services”). After a few weeks of making sure all was well, I and my family packed ourselves into a car, drove to Nashville, and the business carried on the entire time. We were living in the future.
So why, 3 years later, did I just spend the better part of a month moving all our infrastructure back down to our own servers again? Basically, it came down to cost, speed, and the ability to grow.
Bandwidth and Storage Costs S3 — storing files up on Amazon’s virtual drives — is pretty cheap; what isn’t cheap is the bandwidth required to serve them up. If you download a full set of Archive Edition installers, for instance, it costs us a couple of bucks in bandwidth alone. Multiply by thousands, and things start adding up. The real killer, however, was the massive amount of web traffic caused by the combination of cover downloading and serving up image requests to image-heavy websites like ComicBase.com and AtomicAvenue.com. In a typical month, our data transfer is measured in the Terabytes–and the bandwidth portion of our Amazon bill definitely had moved into “ouch!” territory.
We were also paying the price for the promise we’d made to give each of our customers 2GB of allocated cloud storage to store database backups. When we were buying the hard drives ourselves, this wasn’t a super expensive proposition. But when we were now renting the space on a monthly basis from Amazon, we wound up effectively paying the price of the physical hardware many times over during the course of a year.
The Need for Speed Our situation got tougher when we decided to add the ability to have ComicBase Pro and Archive Edition automatically generate reports for mobile use each time users saved a backup to the cloud. This let us give customers the ability to always have their data ready when they viewed your collection on their mobile devices, without needing to remember to save their reports ahead of time. It’s a cool feature–one which I use all the time to view my own collection–but it required a whole new set of constantly-running infrastructure to pull off.
Specifically, we had to create a back-end reporting process (“Jimmy” — after Jimmy Olsen, the intrepid reporter of Superman fame). Jimmy’s job is to watch for new databases that had been backed up, look through them, and generate any requested reports–many for users with tens of thousands of comics in their collections. Just getting all the picture references together to embed into one these massive reports could take 20 minutes on the virtualized Amazon systems.
Even with the “c4 large” compute-oriented server instances we wound up upgrading or Amazon account to, this was a terribly long time, and often left us with dozens of reports backed up awaiting processing. We could of course upgrade to more powerful computing instances, faster IO throughput allocations, etc., but only at an alarming increase in our already considerable monthly spend.
With terabytes of stored data, an escalating bandwidth bill, and all our plans for the future requiring far more resources than we were already using, it was time to start looking for alternatives.
Do it Yourself When we launched ComicBase 2020 just before this past Halloween, we tried a very brief experiment in at least moving the new download images off Amazon and hosting them on a Dropbox share to save on the bandwidth bill.
The first attempt at this ended less than a day after it was begun, when I awakened to numerous complaints that our download site was offline, and a note from Dropbox letting us know that we’d (very quickly) exceeded a 200 GB/day bandwidth limit we hadn’t ever realized was part of the Dropbox service rules. (I could definitely see their point: they were also paying for S3 storage and AWS bandwidth to power their service–albeit at much lesser rates than us, thanks to bulk discounts they get on the astonishing amount of data they move on a daily basis). Unfortunately, there was no way to buy more bandwidth from Dropbox, so after one more day of, “maybe it’s just a fluke since we just launched” thinking–followed a day later by getting cut off by Dropbox again–we abandoned that experiment.
After a couple of days of moving the download images back up to S3 (and gulping as we contemplated the bandwidth bill implications), we wound up installing a new dedicated internet connection without any data caps, and quickly moved a web server to it whose sole purpose was to distribute disk image downloads.
Very quickly, however, we started the work to build custom data servers, based off the fastest hardware on the market, and stuffed full of ultra-fast NVMe SSDs (in RAID configuration, no less), as well as redundant deep storage, on-premise storage arrays, and off-premise emergency backup storage. All the money for this hardware wound up going on my Amazon Visa card, and ironically, I would up with a ton of Amazon Rewards points to spend at Christmas time, courtesy of the huge hardware spend.
After that began the work of moving first the database, then the email, web, and FTP servers down to the new hardware. I’ll spare you the horrific details here, but if anyone’s undergoing a similar move and wants tips and/or war stories, feel free to reach out. The whole thing from start to end took about 3 solid weeks, including a set of all-nighters and late-nighters over this past long weekend to do the final switch-over.
As of this morning at 2AM, we’d moved the last of the servers off of Amazon’s cloud, and are doing all our business once again, on our own hardware. Just before sitting down to write this, I scared myself silly once more as I shut down the remote computer which had been hosting ComicBase.com and AtomicAvenue.com on Amazon’s cloud. And once again, I started to breathe normally again when I was able to successfully fire up a web browser in the office and see that the sites–and the business–were still running: once again on our own hardware.
So far, things seem like they’re going pretty well. The new hardware is tearing through the reporting tasks in a fraction of the time it used to take; sites are loading dramatically faster; and the only real technical issues we encountered were a few minor permission and site configuration glitches that so far have been quickly resolved.
Unless it all goes horribly pear-shaped in the next few days, I’ll be deleting our Amazon server instances entirely. While I’m definitely appreciating the new speed and flexibility the new servers are giving us (and I’m looking forward to not writing what had become our business’ biggest single check of each month), I still have to hand it to the folks at AWS: you guys do a heck of a job, and you provided a world class service when we needed you most. I also love that a little Mom-n-Pop shop like ourselves could access a data center operation that would be the envy of the largest corporate environments I’ve ever worked in. With the incredible array of services you now provide, it wouldn’t surprise me in the least if we didn’t wind up doing business again in the future.
For the past few weeks, we’ve been engaged in a big move of our servers back down from the Amazon cloud to on-premises servers. While Amazon runs an amazing service, the bandwidth bill for ComicBase is a killer, and we can afford to throw way more processing power and disk storage at it if we simply buy the hardware than if we rent it from Amazon. By using on-premise hardware, we get to go way faster, way cheaper, and keep more control of our data.
Although I’m quite looking forward to not writing my largest single check of each month to Amazon, Running your own gear means running your own data center–with all that entails. Namely, you’re completely responsible for everything from backups to firewalls to even power. (I used to keep a generator and set of power cords at the ready back in California for when our infamous “rolling blackouts” would hit, in order to minimize server downtime).
On the backup front, we’re actually improving our position, using multiple layers of RAID, traditional disk backups, and off-site cloud storage. Basically, even if the place burns to the ground, we should be able to pick up the pieces and carry on pretty quickly.
What really gets old, however, is dealing with the network security foo. Unless you’ve run a site yourself, it’s hard to believe how fast and frequent the attacks come on every part of your system, courtesy of our friend the internet.
Mind you, these are not, for the most part, targeted attacks by the sort of ace hackers you see on TV and movies. Instead, it’s a constant barrage of “script kiddies” — drones and bored teens using automated “hacking” tools to assault virtually every surface of a publicly facing server using the computer-equivalent of auto-dialers and brute-force guessing.
Whether it’s the front-facing firewall, web sites, email servers, or what have you, looking at the logs shows that mere hours after the servers went live, they were being perpetually pounded with password-guessing attacks, attempts to relay spam, port scans, etc. None of these stood a chance in hell of succeeding (sorry, kiddies, the password to our admin account is not “password”) but it was amazing to see how quickly “virgin” servers, on new IP addresses, started getting pounded on. In one case, we started seeing automated probes of a server before it had even gone live to our own production team!
All this is to say that it’s a jungle out there, folks. For heaven’t sake use decent passwords (a good start: don’t let your password be any word that’s in a dictionary); change the default account passwords and user names for all your various networking hardware, don’t re-use passwords from system to system, and look for a good password manager to keep them all straight for yourself (I’m personally partial to 1Password, although I got hip to that program before they switched to a monthly billing model).
And yeah, watch those server logs. Most of the script-kiddie attacks are about as effective as the robocalls which start with a synthesized voice claiming, “HELLO, THIS IS IRS CALLING. YOU ARE LATE IN MAKING PAYMENT.” But we’ve also seen some more sophisticated attacks employing publicly known email addresses, names of company officers and more. Bottom line: watch yourself when you’re on the internet, and realize the scumbags are always looking for targets. Don’t make it easy on them.
Possibly the first time I feel like I’ve truly gotten my tax dollar’s worth in pure entertainment:
Not only is this just an amazingly funny takedown of a breathtakingly stupid piece of proposed legislation–but it also introduced me to what is apparently a whole line of quite–umm–striking work from artist Jason Heuser, whose modern-day masterworks include:
George Washington wielding a mini-gun! Bill Clinton, Lady-Killer!Teddy Roosevelt Taking Down Bigfoot!And George W. Bush with Twin Revolvers, Riding a Shark!
And here, of course, is the patriotic image which started it all:
Ronald Reagan, Riding a Velociraptor, firing a machine-gun, with a rocket launcher on his back.